

Chaos in the Cloud
A Introduction to Chaos Engineering and Amazon's Fault Injection Service
Table of Contents
This is the first in a series of articles looking at chaos engineering in general, and in particular how we can use Amazon’s Fault Injection Service to test the resilience of our AWS systems.
When I first started developing, we wrote huge, monolithic applications either running locally on our desktops, or in our datacenters. We’d write applications that had tens or even hundreds of thousands of lines of code. However, the applications we wrote usually consisted of a single component, maybe two if we used a database, handling all of the logic and functionality within a single application. Whilst this meant that we usually had complex, hard to navigate, code bases, it did mean that in terms of architecture, our applications were relatively simple.
Today, we build systems with multiple components such as databases, message queues, application servers, all communicating across networks. The functionality for the systems is often broken down into microservices, each handling small subsets of the overall problem space. We usually deploy to cloud, which allows us to build more scaleable, resilient systems. This approach also means we can accelerate our development processes as we can allocate multiple individuals or teams to work on different parts of the system.
The evolution of testing approaches
Looking back at those monolithic applications, testing tended to be a very manual process. We’d have test writers who’d review the requirements and write test specifications. They’d outline the steps to be carried out to test parts of the system, and then the testers would work through the list of steps, noting whether the system behaved as expected. If there were discrepancies, they’d raise defects, and the developers would fix the issues.
As software development has matured, we’ve moved on and added new approaches to our testing. We’ve introduced unit tests which allow us to demonstrate that small, isolated pieces of code work as we expect. Some of us even look to a Test-Driven Development (TDD) approach, where the first code we write is tests. Often these unit tests are then executed automatically as part of a pipeline, stopping deployment of new code until all tests pass successfully.
We’ve also introduced integration testing, to ensure that our code works with other systems and applications and doesn’t introduce issues. We’ve also introduced performance testing, where we look to see if our code behaves in a performantmanner under load.
However, one area that we’ve not been able to address until recently is thinking about how the infrastructure running our code behaves. We’ve not been very good at looking at how all of our separate components work together, especially if they don’t behave as expected - how many times have projects been delayed,or even cancelled, because when using the application in anger, there were unexpected delays in communications, or parts of our code couldn’t handle failures elsewhere in the system?
Using chaos to bring confidence
As more companies started to build complex, distributed systems, people started to consider how they could test how resilient their systems were.
It’s probably not surprising that Amazon was one of the earliest companies to think about this, and in 2003, Jesse Robbins, introduced the idea of “Game Day”1, an attempt to increase reliability by regularly introducing failures in their systems.
However, it wasn’t until 2011, when Netflix started to migrate to the cloud, that the idea of ‘Chaos Engineering’ started to become widespread, primarily due to a set of tools introduced by Netflix. In a blog post 2, engineers at Netflix introduced the idea of a toolkit, the so-called ‘Simian Army’ that could be used to generate failures in their systems.
The ‘Simian Army’ was an open-source set of tools that could be used to introduce different types of failures into Netflix’s systems. For example, ‘Chaos Monkey’ would randomly terminate instances in their production environment, ‘Latency Monkey’ would introduce delays in network communications, and ‘Chaos Gorilla’ would simulate the loss of an entire AWS region.
Over time, this approach became known as ‘Chaos Engineering’, an approach that can be defined as
The discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.3
Many people adopted the toolset, and started to use it directly, or to build their own scripts to introduce failures in a managed way to test the resilience of their systems. However, this all needed a lot of effort and resources to run and manage.
Undifferentiated heavy lifting to the rescue
Amazon Web Services has a concept called ‘undifferentiated heavy lifting’. This is the idea that when many of it’s customers are expending a lot of effort to solve the same problem, that AWS should look to solve the problem for them, allowing them to focus on their core business.
Amazon was aware that many of it’s customers were looking at the approach of Chaos Engineering, and in 20214, they introduced a new service, initially called the ‘Fault Injection Simulator’, but quickly renamed to the ‘Fault Injection Service’ (FIS).
FIS was designed to allow customers to perform controlled, repeatable experiments on their workloads; introducing errors and issues and reviewing how their systems responded.
Creating the perfect recipe for chaos
The core of FIS is the concept of an ’experiment’. You can think of this as a recipe - you’ll need ingredients (or targets as they’re known in FIS) which are the things you want to test, such as EC2 instances, RDS databases, lambdas or even the underlying network. Once you have your list of ingredients, you then need to understand thesteps to combine them - these are the actions that you’ll take, such as introducing latency, or killing an instance.
In the same way that we gather recipes in a cookbook, we can store our experiments in templates so that we can run them again and again, knowing we can re-create our testing masterpieces perfectly each time.
These templates are made up of a number of different components with the first 3 being required, and the remainder being optional. Let’s look at these below:
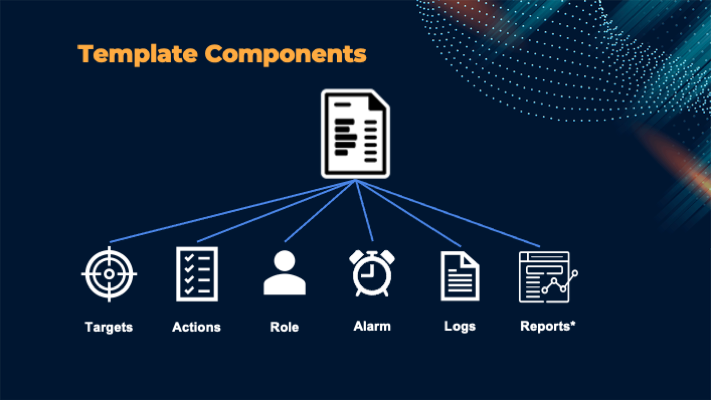
- Targets - as mentioned above, these define the resources that you want to test with a full list being available at https://docs.aws.amazon.com/fis/latest/userguide/targets.html#resource-types. Once you specify which type of resource you want to test, you can then filter the resources you want to test by tags, or by specifying the identifier such as an EC2 instance id.
- Actions - these describe what you’d like to do to your targets. There are a number of different actions available, depending on what type of target you’re testing - the full list is available at https://docs.aws.amazon.com/fis/latest/userguide/fis-actions-reference.html.
- IAM Role - when you run an experiment, FIS will use a role you define to perform the experiment. This means that the role will need the appropriate permissions to interact with the resources AND also FIS itself.
- Stop Conditions - there might be times when you want to halt an experiment, for example if it starts to impact on a running environment. Stop Conditions allow you to link a pre-defined CloudWatch alarm to your template. Then, if that alarm is triggered during the experiment run, it will halt the experiment.
- Logs - when you come to run your experiments, you may want to capture logs to understand what happened during the experiment. FIS allows you to capture logs to an S3 bucket or to CloudWatch, and they’ll capture information such as the start and end of the experiment, the resources targeted, and the actions taken.
- Reports - just before re:Invent 2024, new functionality was announced which allows FIS to generate a report that can be shared with others to document the experiment results. FIS allows you to generate a report in PDF, optionally including graphs from CloudWatch in a format that can be shared with others - for example a change review board, or during a code review.
- Other options - in addition to the above items, there are other options available in templates, such as defining how long an experiment should run, how many items should be targetted (for example, 75% of an autoscaling group).
Once you’ve defined a template, these can be run multiple times, either manually, part of a pipeline or at scheduled times. The results of these runs are then stored and can be reviewed.
Pricing
As with most AWS services, you’ll only pay for what you use. With FIS, the basic charge is $0.10 per minute per action per account.
Coming soon!
I hope you find this overview of Chaos Engineering and Amazon’s Fault Injection Service useful. In the next post, coming soon, we’ll look at how we create a template to test an EC2 autoscaling group, and then test how well the group responds to a failure.